
Le Chaos Kong est une des pratiques appliquée dans l’approche du Chaos engineering. Cette pratique extrême du devops permet de s’imposer d’avoir des offres de qualité.
Le Chaos Kong
Le chaos kong est très proche de son grand frère le chaos monkey et très similaire au Chaos Gorilla. La principale différence se situe au niveau de la grandeur des pannes ; d’ailleurs « Kong » parait plus gros que « Gorilla » qui lui même parait plus gros que « Monkey« .
Revenons aux origines du terme de Chaos Monkey. Voici l’explication d’Antonio Garcia Martinez dans son livre qui explique pourquoi la solution s’est appelée Chaos Monkey :
« Imaginez un singe s’introduisant dans un data center, ces « fermes » de serveurs qui hébergent toutes les fonctions critiques de nos activités en ligne. Le singe arrache au hasard des câbles, détruit des appareils et retourne tout ce qui lui passe par la main. Le défi pour les responsables informatiques est de concevoir le système d’information dont ils ont la charge pour qu’il puisse fonctionner malgré ces singes, dont personne ne sait jamais quand ils arrivent et ce qu’ils vont détruire. »
Voici le raison très simple de cette appellation ; elle pourrait surprendre quand on ne connait pas les raisons de son existence. Je vous laisse imaginer l’image en remplaçant le singe par un gorille.
En effet, le terme de gorille est exactement la représentation métaphorique que veut donner cette autre solution pour tester la résilience en cas de panne.
le chaos kong, c’est la solution mondiale
En effet, cette solution est similaire aux deux autres mais permettra de tester la résilience du système dans son ensemble sur un ensemble encore plus grand. Avec le Chaos Kong on va tester la résilience en cas de panne sur une région complète d’AWS. Il va ainsi mettre en arrêt une région dans sa totalité afin de tester la résilience du service complet.
Voici ce que les deux autres pratiques vu précédemment testent :
- Chaos Monkey : tester des pannes d’instances ou de serveurs
- Chaos Gorilla : tester la résilience en cas de panne sur une zone complète d’AWS (une région est composée de plusieurs zones)
Si votre système arrive à survivre à une telle panne provoquée volontairement par le chaos kong, c’est qu’il est très résilient. Soyons clair : rare sont les entreprises capables d’avoir un système survivre au chaos kong.
Mais attention de ne pas se tromper ; le chaos kong ne remplace pas le chaos monkey. Certains services peuvent survivre d’un chaos kong et ne pas survivre à un chaos monkey. La notion d’échelle teste des notions d’architectures très différentes.
Les zones et régions sur AWS
Voici le schéma proposé par Amazon pour que vous comprenez bien la notion de région :
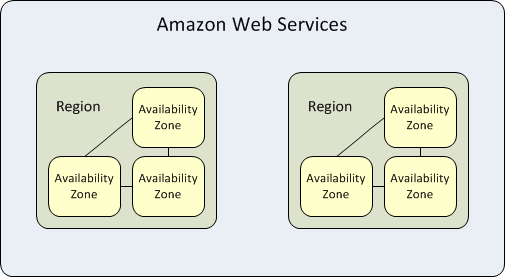
Avec un système fonctionnant en plusieurs zones voire en plusieurs régions (on parle bien de régions dans le monde), votre système devrait être assez résistant. Cependant, cela implique une bonne capacité de scalabilité car lorsqu’une région tombe, les autres région doivent faire face à une éventuelle surcharge de travail.
Mais ce n’est pas couteux ?
Les clouds d’aujourd’hui permettent de limiter les frais si on compare aux années 90 ; cependant, la mise en place de services capables de faire face aux solutions du chaos engineering a un coût.
Cependant, ce coût permettra d’avoir des systèmes beaucoup plus résiliants ; cela permettra :
- d’éviter la déception des clients (en cas de panne)
- de limiter les coûts de maintenances futures
- de ne pas être surpris d’avoir des pannes en cascade
Est-ce que le coût n’est pas un investissement gagnant au final ?
conclusion chaos kong
Utilisez-vous le chaos kong dans vos entreprises ? Pensez-vous que le chaos kong est un extrême ou devrait devenir une norme pour s’assurer de la qualité de service ?
Lien utile lié au chaos kong : outil à télécharger

Soyez le premier à commenter