
Le Blue Green deployment devient un pattern de déploiement très répandu dans le monde du devops qui a été initialement proposé Jez Humble et David Farley dans leur livre Continuous Delivery datant de 2010. Cependant si ce pattern est devenu un classique des meetup Devops, on ne la rencontre qu’assez rarement dans les entreprises.
Qu’est-ce que le Blue Green deployment ?
Dans le monde du devops, nous aimons dire que nous pouvons déployer sans jamais interrompre les services. C’est forcément une notion très vendeur pour de nombreuses personnes au sein de nos entreprises. C’est le concept du Zero Downtime Deployment (ZDD) qui a pour but d’offrir la qualité de pouvoir livrer régulièrement de façon transparente et de façon quasi instantanée.
De façon simplifiée, le Blue Green deployment propose d’avoir un environnement de production identique à celui qui est utilisé par les utilisateurs qui recevra une nouvelle version. Il sera essentiel d’avoir un outil de routage qui saura passer d’un environnement de production à l’autre afin d’avoir la nouvelle version de façon totalement transparente.
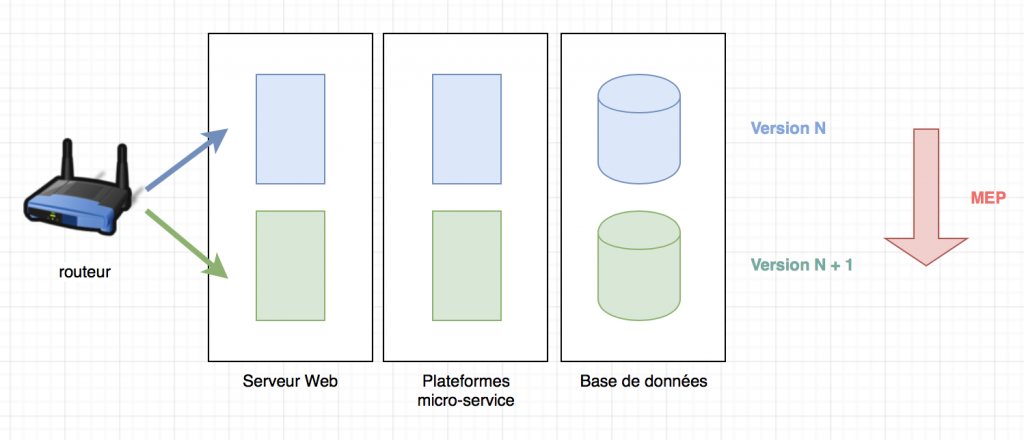
Ce schéma simplifie l’explication précédente ou le Green est la duplication de la production qui va recevoir la nouvelle version de notre architecture pendant que les utilisateurs sont routés vers le Blue.
Ce concept n’est pas plus compliqué que ça et certaines entreprises utilisaient déjà des principes similaires il y a 10 ans de façon moins formalisée (mais à l’époque cela avait un véritable coût non négligeable car on parlait de serveurs physiques).
Quand tous les contrôles nécessaires sont réalisés, vous pourrez dire à votre routeur d’amener les utilisateurs vers l’environnement Green. Avec cette méthode, le rollback est relativement simple à mettre en place, car il suffira de dire au routeur de revenir sur la version Blue.
Ces actions de routage sont instantanées pour les utilisateurs.
Pour ceux qui sont imaginatifs, ce concept pourrait même vous permettre de faire de l’A/B Testing car il suffira de router % de vos utilisateurs sur le Green et % de vos utilisateurs vers le Bleue.
Premiers problèmes rencontrés avec le Blue Green deployment
Si au premier abord ce fonctionnement parait très simple, il y a rapidement des problèmes que vous rencontrerez si vous ne les anticipez pas en avance.
Les sessions utilisateurs
Le problème le plus classique est la gestion des sessions. Comment faire migrer un utilisateur du Green au Blue sans que la personne soit déconnectée ?
Il existe deux méthodes classiques comme celle de mettre la session dans un cookie et l’autre d’appeler un « dépôt » indépendant de type Memcache, Redis… Dans ce cas les utilisateurs passeront du Blue au Green sans même s’en rendre compte.
Les bases de données pour le Blue Green deployment
Autre soucis classique, comment faire pour que les transactions commencées en Blue dans une base de données SQL puissent s’appliquer en Green si elles se commencent et se terminent après le déploiement ?
1/ base de données indépendante pour le Blue Green deployment
Les avantages de sortir la base de données SQL du pattern Blue Green sont de ne pas avoir le besoin de mettre en place un concept de synchronisation entre la base de données Green et la base de données Blue et également de ne pas avoir de rupture du service.
Cela impliquera d’autres problématiques par contre que nous allons voir ci-dessous.
Les autres soucis que cette dernière méthode impliquera sera celle d’un changement de modèle dans la base de données.
L’idéal sera alors d’avoir un Front qui fera son possible pour appeler des bases de données NoSQL qui n’ont pas de soucis avec les modèles (CouchBase, MongoDb par exemple qui sont flexibles sur les données). Les bases de données SQL iront alimenter les bases de données NoSQL.
Il faudrait aussi faire des insertions avec des outils tels que RabbitMQ qui permettraient de créer une deuxième pile avant de démarrer la mise en production afin de maximiser les chances de n’avoir aucune perte de données. La base de données SQL ne sera alimentée que par des entrées de rabbitMQ. Cela permet de ne pas être dépendant du modèle de la base de données SQL.
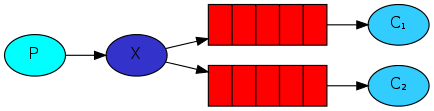
Il existe une autre méthode plus simple et moins coûteuse. Celle-ci permet de faire cette séparation des bases de données par rapport aux environnements Blue Green. Il faut rajouter des champs et ne jamais enlever des champs du SQL voire des API associées. C’est plus traditionnel mais ça fait le job.
2/ base de données insérée dans le Blue Green deployment
Ce concept a l’avantage de limiter les risques sur les changements de modèles de bases de données SQL ; par contre cela implique de gros besoins de synchronisation dans tous les sens.
C’est dans la théorie le meilleur modèle, mais c’est le plus complexe à mettre en place. Je vous conseille fortement de bien réfléchir avant de faire ce choix qui est assez complexe à gérer.
Faire du Canary Release
Le canary Release est un pattern qui permet de mettre une petite tranche de population sur la version N + 1 ; la tranche restante restera temporairement sur la version N. Cela permet de tester si tout va bien avant de déployer sur l’ensemble des utilisateurs.
Facebook utilise ce pattern pour déployer un jour avant sur nouvelles versions pour les employés de l’entreprise. C’est un concept similaire de l’A/B Tasty que nous avons vu plus haut.
Faire du Dark launch
Le Dark Launch est également un pattern associé au Blue Green deployment ; il propose de switcher progressivement la population de la version N à la version N+1. Cela permet de tester progressivement notre nouvelle version qui pourrait par exemple rapidement montrer des soucis utilisateurs.
Conclusion Blue Green deployment
Vous avez découvert ce pattern Blue Green deployment qui fait tant parler de lui ; il s’est popularisé avec le mouvement devops. Des outils comme HAProxy sont très utiles au passage pour faire ce fameux routage entre le Blue et le Green.
Avez-vous du Blue Green deployment chez vous ? Comment avez-vous géré les bases de données SQL ?



1 Rétrolien / Ping