
Dans certains projets informatiques, il n’est pas toujours possible de quantifier une demande ; certains développeurs rejetteraient la demande. Le Spike est là pour compenser ce problème.
Vous pouvez regarder la vidéo de La Minute Agile sur le sujet :
Types de demandes
Si j’ai une demande qui implique de la recherche, il est évident que mettre des points d’effort sur cette demande n’aurait pas de sens. Si parfois les solutions sont automatiquement proposées par les développeurs, certaines problématiques sont bien plus complexes à résoudre.
Ce type de demande ne sont pas rares sur des projets comme en « Big Data » ou dans les grandes structures où on sait ce qu’on a besoin ; cependant que nous n’avons aucune idée de comment récupérer les données nécessaires… Dans ce cas, mettre des points d’effort sur le ticket n’a pas de sens.
Nous pourrions aussi avoir ce soucis quand on a besoin de faire un choix entre plusieurs solutions mais que cela implique des tests et de la recherche complémentaire.
Un autre cas intéressant d’un besoin de spike peut apparaitre : une user-story est trop grande, il faudra étudier pour la découper voire pour mieux la définir.
Comment se gère un Spike ?
Contrairement à une user-story, on va « timeboxer » le spike afin de bien borner celui-ci. On va définir en début de sprint que celui-ci fera X heures/homme voire X jours/homme.
Dans un projet où on fait des estimations
Cette méthode permettra de garder une bonne cohérence des roadmaps et des planifications ; en Scrum, nous utilisons la somme des points d’effort et la capacité pour planifier. Nous retirons le temps pris des spike du nombre de jour homme utilisé pour calculer la capacité.
Rappel du calcul utilisé pour planifier :
C = V1 / P1 * P2
- C = la capacité soit la somme des points d’effort autorisées pour le Sprint 4
- V1 = somme totale de la vélocité des précédents 3 sprint
- P1 = nombre de jour de dev. des 3 précédents Sprint
- P2 = nombre de jour de dev. du prochain Sprint
Dans un projet #NoEstimate
Dans un projet où nous n’estimons pas, les impacts des spike ne sont pas très importants. Cependant, il est quand même conseillé de « timeboxer » ses spike car les développeurs pourraient passer un temps indéfinie pour rechercher des choses. Il est souvent utile de cadrer les développeurs sur ce point car ils sont souvent dans l’envie de trouver la solution optimale et/ou de tester de nouvelles choses attractives.
Visuellement ?
Pour représenter les Spike, il est souvent intéressant de les faire sur des post’it d’une autre couleur comme ceci :
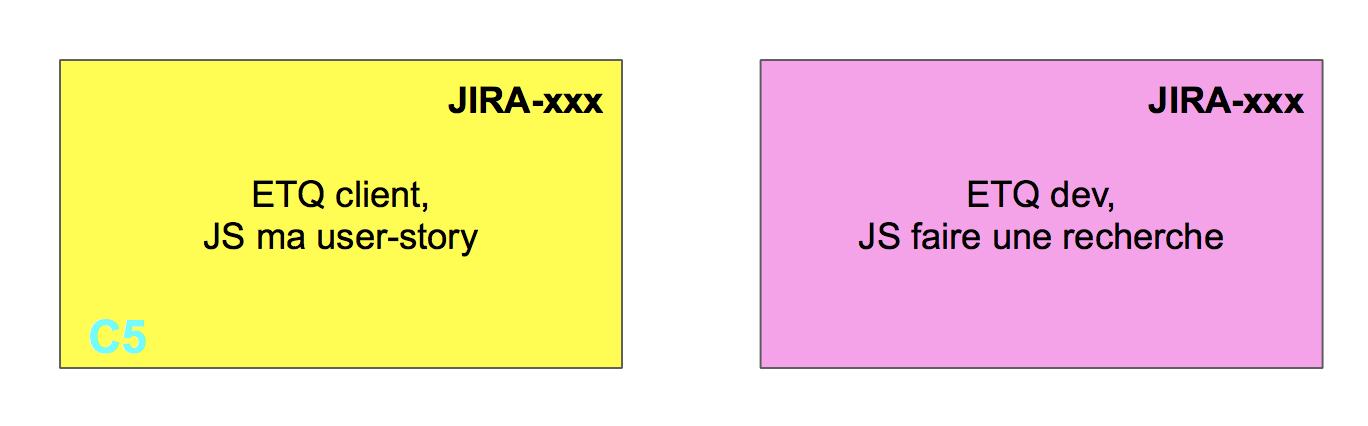
Pour l’écriture des Spike, j’aime bien garder le même format que les user-story afin de garder une cohérence générale sur les demandes. Par contre, le destinataire ne sera pas forcément un persona car les développeurs ou le Product Owner pourraient être la cible du Spike.
Spike informatique : bien ou pas bien ?
Certains n’aiment pas intégrer des spike mais c’est selon moi une bonne méthode pour avancer sur certains sujets. Il est préférable de faire un spike et de ne pas mettre de points d’effort au maximum sur une demande qui n’est pas estimable dans les faits.
Il est évident que les spike doivent rester limités et ne doivent pas prendre le dessus par rapport aux user-stories. Si c’était le cas, il faudrait peut-être voir pour faire envisager une phase de framing agile.
N’hésitez pas à profiter des spike si votre contexte en a besoin çar cette méthode permet de combler certaines problématiques rencontrées lors de projets Scrum.



Superbe article, je ne connaissais pas les spikes et sincèrement il nous arrive de mettre une grosse complexité sur une us de type recherche qui au final se fait en moins d’une heure et du coup coup on passe pour des menteurs (voir pire) merci pour l’info 😉
Merci Alexis. En effet le Spike permet souvent de répondre à certaines problématiques comme la tienne. Merci pour ton retour sur le sujet car en effet, ça peut aussi éviter des tensions 🙂
Bonjour, je vous remercie pour cet article sincèrement cela m’a aidé surtout que j’avais pas la notion de spike en tête on l’a jamais utilisé mais apparemment on aura recours a cette méthode, sinon est ce que vous avez déjà traité le sujet des points d’effort genre des astuces pour mettre tel valeur comme point d’effort d’une User Story ou Technical Story.
Voici un article que je viens d’écrire qui répondra surement à tes questions : COMMENT METTRE DES POINTS D’EFFORT DANS UNE ÉQUIPE ?
si tu as encore des questions sur le sujet, n’hésite pas à mettre un commentaire sur l’article.
Bonjour,
Très intéressant cette présentation du spike.
Nous nous l’utilisons mais je ne sais pas si correctement tout le temps.
Lorsque nous avons le doute de si une US ou bug est réalisable (techniquement ou autre) nous utilisons le spike. En générale le résultat est une information (sous différents formats) qui sera utilisé plus tard pour réaliser la US réelle.
Mais souvent elle est aussi utilisé lorsqu’on est pas sûre de pouvoir dans le sprint faire un livrable avec dev + QA à la fin du sprint car il y a de l’inconnu. Et c’est là où je doute de notre façon de faire.
J’entends que si inconnu il y a le spike aide à éloigner l’inconnu, mais ne devrions nous pas après (sprint suivant) faire la US réelle sur laquelle travailler (faire le dev et la QA)?
Souvent le résultat du spike est une livraison de dev prête à passer en QA (comme les autres US) et souvent sans acceptance criteria puisque c’est un Spike.
Qu’en penses-tu?
Merci de ton opinion
Désolé, j’a pas bien compris l’utilisation :S